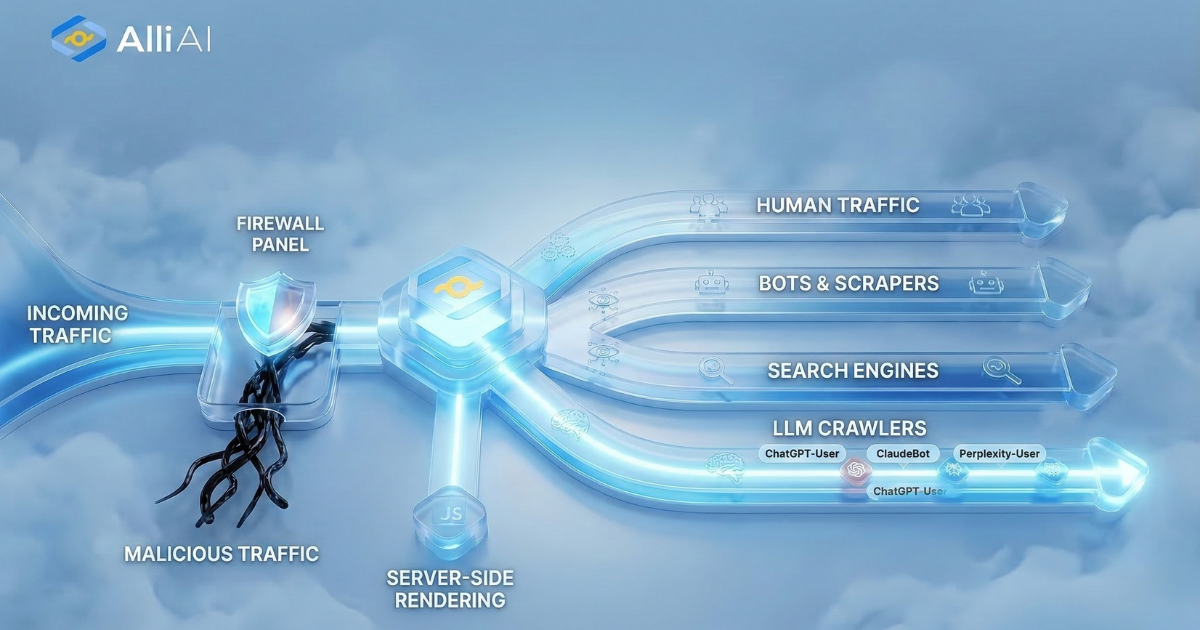
What Does Crawl Budget Mean?
Crawl budget refers to the number of pages on a website that a search engine’s crawler, like Googlebot, will scan and index within a certain period. This budget is influenced by the site’s size, the speed of its server, and how important Google deems the content. Having a good crawl budget ensures that new and updated content on your website gets discovered and indexed quickly.
Where Does Crawl Budget Fit Into The Broader SEO Landscape?
Crawl Budget refers to the number of pages a search engine bot will crawl and index on a website within a given timeframe. It fits into the broader SEO landscape as it directly impacts how often and how thoroughly a site is indexed. A higher crawl budget means more pages can be crawled frequently, making recent updates more likely to be recognized and indexed swiftly. This is particularly crucial for large websites with thousands of pages, where a limited crawl budget can mean that significant portions of the site aren’t indexed regularly, thus affecting the visibility of those pages in search results.
Effective management of the Crawl Budget involves ensuring that web server errors, long page load times, and unnecessary redirects are minimized, as these can consume crawl resources and limit the efficiency of search engine bots. Additionally, proper use of the robots.txt file and strategic use of noindex tags can help focus crawling efforts on the most important pages, optimizing how crawl budget is utilized and enhancing overall SEO performance. This process ensures that a site’s most valuable content is prioritized for indexing, thereby improving search visibility and performance.
Real Life Analogies or Metaphors to Explain Crawl Budget
Crawl Budget is like the allowance a parent gives to a child for a candy store. The store (your website) has various candies (web pages), but the child (search engine bot) only has a limited amount of money (crawl budget) to spend. So, they must choose wisely which candies to buy (which pages to crawl) based on what they like best and think are most valuable.
How the Crawl Budget Functions or is Implemented?
1. Crawl Rate Limit: Search engines limit the rate at which they crawl pages on a website to avoid overwhelming the site’s server. This limit is adjusted based on how quickly a site responds to requests. Slow responses lead to reduced crawl rates.
2. Crawl Demand: Search engines prioritize crawling pages that are more popular or have been recently updated. Pages deemed less important may be crawled less frequently.
3. Crawl Health: Errors such as high response times, 5xx errors, and frequent connection timeouts can reduce the crawl budget allocated to a website.
4. Site Architecture: Websites with a logical structure and clean URLs are easier and faster to crawl. Deeply nested pages or those accessible only through complex navigation paths consume more crawl budget.
5. Duplicate Content: Sites with high levels of duplicate content may see their crawl budget wasted. Search engines prefer to avoid crawling substantially similar pages multiple times.
6. Robots.txt and Meta Tags: The use of robots.txt files to block crawling of specific sections of a site and the use of noindex tags can help manage and optimize the crawl budget by preventing search engines from crawling irrelevant or non-essential pages.
7. Sitemaps: Providing a well-structured sitemap can help search engines prioritize which pages to crawl and when, making more efficient use of the crawl budget.
8. Internal Linking: A strong internal linking structure can help search engines discover new content and re-crawl important existing content, thus optimizing the distribution of crawl budget across the site.
9. Overall Site Traffic and Engagement: Websites that attract more traffic and have higher user engagement may receive a higher crawl budget as these factors indicate the site’s value to users.
10. SEO Optimizations: Implementation of SEO best practices like optimizing content, improving mobile usability, and increasing page speed can indirectly affect crawl budget by enhancing the accessibility and user experience of the site, leading to higher crawl demand.
Impact Crawl Budget has on SEO
Crawl Budget refers to the number of pages on a website that search engine bots crawl and index within a given time frame. The impact of crawl budget on a website’s SEO performance, rankings, and user experience is significant:
1. SEO Performance: If a search engine allocates a high crawl budget to a site, more pages get indexed, increasing the likelihood of these pages showing up in search results. Conversely, a low crawl budget can result in important pages not being indexed, reducing their visibility in search results.
2. Rankings: Websites with frequently updated content or large numbers of pages might not have all their pages crawled and indexed if their crawl budget is too low. This can prevent high-quality or relevant pages from ranking well in search engine results pages (SERPs), as they might not be indexed in time to compete for rankings on specific queries.
3. User Experience: Indirectly affects user experience; for instance, if important pages are not indexed due to limited crawl budget, users may not find the information they seek via search engines, leading to a poor user experience. Additionally, outdated or redundant pages that waste crawl budget could lead to more current pages not being crawled and indexed promptly, impacting the freshness of the content available to users.
SEO Best Practices For Crawl Budget
1. Audit Website Crawlability:
– Use tools like Screaming Frog or Google Search Console to identify crawl errors.
– Fix any 4xx errors, 5xx server errors, or broken links.
2. Control Crawl Rate:
– Adjust crawl rate settings in Google Search Console if necessary.
3. Improve Site Structure:
– Ensure a logical hierarchy in the website’s architecture.
– Use breadcrumb navigation and a sitemap to guide crawlers.
4. Optimize Internal Linking:
– Create comprehensive internal links using relevant anchor texts.
– Ensure no orphan pages or dead-end links exist.
5. Use Robots.txt Strategically:
– Disallow crawling of irrelevant or duplicate pages.
– Keep the robots.txt file updated and error-free.
6. Leverage URL Parameters in GSC:
– Use Google Search Console to inform Google how to handle URL parameters.
– Prevent crawling of duplicate content generated by parameters.
7. Implement Pagination Tags Properly:
– Use rel=”next” and rel=”prev” links to help Google understand pagination.
8. Prioritize Important Pages:
– Enhance the crawl frequency of high-priority pages via better linking or sitemap prominence.
9. Monitor Server Response Time:
– Use tools like Google PageSpeed Insights to check and improve server response times.
– Optimize database and reduce server load if necessary.
10. Optimize Content Regularly:
– Update or remove outdated content.
– Merge or canonicalize near-duplicate pages.
11. Manage Redirects:
– Limit the use of unnecessary redirects, particularly chains.
– Ensure that redirects are 301 (permanent) where suitable.
12. Enable Compression and Caching:
– Use gzip or Brotli compression to reduce page size.
– Implement browser caching policies to improve load times.
13. Avoid Deep Nesting of URLs:
– Keep the depth of important content within 3 clicks from the homepage.
14. Limit Excessive Dynamic URL Generation:
– Reduce the number of dynamic URLs that require high server resources.
15. Regularly Monitor and Adjust Strategy:
– Regularly check the Index Coverage report in Google Search Console.
– Adjust strategies based on analytics and crawler behavior.
Common Mistakes To Avoid
1. Allowing Low-Value-Add URLs to be Crawled: Avoid wasting crawl budget on pages that don’t benefit your site’s SEO. Implement ‘noindex’ on low-quality pages or use robots.txt to prevent search engines from crawling them.
2. Poor Site Architecture and Navigation: Ensure that your site structure is logical and straightforward. Use internal linking wisely to ensure important pages aren’t deep within the site architecture, making them hard for bots to discover.
3. Faceted Navigation and URL Parameters: Too many URL parameters can create massive amounts of duplicate content, which can dilute crawl budget. Use the URL Parameters tool in Google Search Console to help Google crawl your site more efficiently by telling Google which parameters are useful and which to ignore.
4. Excessive On-Site Duplicate Content: Utilize canonical tags to point search engines to the original version of content. This consolidation helps preserve crawl budget by reducing the need to crawl and index duplicate pages.
5. Blocked Resources: Ensure CSS, JavaScript, and image files are accessible to bots as these are important in rendering and understanding your site. Blocking these resources can lead to unindexed pages or incorrectly displayed content.
6. Slow Server Response Times: Improve server response times. A slow response can consume more crawl budget as the crawler spends more time waiting for pages to load.
7. Excessive Redirect Chains and Broken Links: Limit the number of redirects (especially chains of redirects), and fix broken links. Both issues waste crawl budget and can affect user experience negatively.
8. Session IDs in URLs: Session IDs can create massive amounts of duplication and numerous access points to the same content. Where possible, avoid their usage or manage their indexing through the use of cookies instead of URL parameters.
9. Ignoring Crawl Errors: Regularly monitor and fix crawl errors reported in Google Search Console. Ignoring these can lead to wasted crawl budget on problematic URLs.
10. Failing to Update Sitemaps: Keep XML sitemaps up-to-date and error-free. Sitemaps that include non-existent or redirected URLs can misguide crawlers and waste budget. Ensure that the sitemap only contains clean, accessible URLs.