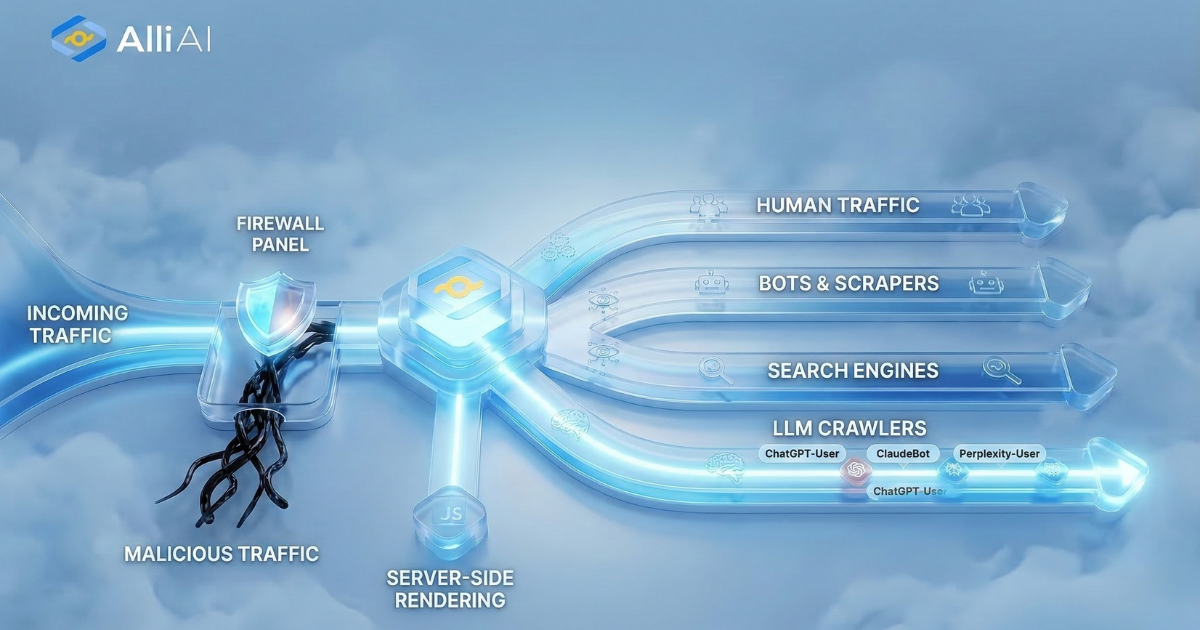
What Does Robots.txt Mean?
Robots.txt is a text file webmasters create to instruct web robots (typically search engine robots) how to crawl pages on their website. The file is used to tell these robots which areas of the site should not be processed or scanned. It helps control the traffic on your server and keeps the content you don’t want appearing in search results private, although it’s not a foolproof method for securing sensitive information.
Where Does Robots.txt Fit Into The Broader SEO Landscape?
Robots.txt is a file that tells search engine crawlers which pages or sections of a site should not be crawled and indexed. This is crucial for SEO as it allows site owners to prevent search engines from indexing duplicate content, private content, or sections of a site that are under development. By directing crawlers away from irrelevant or redundant pages, robots.txt helps improve the site’s SEO by ensuring that only the most valuable and relevant content is indexed and presented in search results. It also helps to manage crawl budget by preventing search engines from wasting resources on unimportant or similar pages.
Real Life Analogies or Metaphors to Explain Robots.txt
1. Robots.txt as a Bouncer at a Club: Consider a nightclub where the bouncer at the door checks your ID to decide whether you can enter. In this analogy, the nightclub is the website. Robots.txt is the bouncer who checks which search engine bots (guests) are allowed to access certain parts of the website (sections of the club). Some areas might be off-limits, just as some directories of a website are disallowed for crawling.
2. Robots.txt as a Do Not Disturb Sign: Imagine staying in a hotel where you put a “Do Not Disturb” sign on your door. The sign tells hotel staff (equivalent to web crawlers) when they are not allowed to enter. Similarly, robots.txt puts this sign on specific parts of a website, informing search engine bots which sections they should not access.
3. Robots.txt as a Librarian’s Instructions: Think of a library where a librarian directs which sections are open for browsing. Robots.txt acts as the librarian, guiding the search engine bots (library visitors) on which parts of the website (book sections) they can access and index.
4. Robots.txt as a Traffic Light: In traffic, a red light tells you when to stop, and a green light tells you when to go. Robots.txt works like a traffic light for web crawlers, signaling when they can enter (crawl) certain areas of a website (traffic lanes) and when they must stop or bypass them.
5. Robots.txt as a Recipe Modifier: Consider a recipe that includes optional ingredients or steps that you might skip based on preference. Similarly, robots.txt allows a website to specify instructions (ingredients) to search engine bots (cooks), indicating which pages or directories can be skipped or need attention.
How the Robots.txt Functions or is Implemented?
1. Location
The robots.txt file must be placed in the root directory of the website (e.g., www.example.com/robots.txt).
2. Access Control
It advises search engine robots (user-agents) which pages or sections of the site should not be processed or scanned.
3. Syntax Components
– User-agent: Specifies the search engine to which the rule applies.
– Disallow: Indicates the directories or URLs that should not be accessed.
– Allow: (Not standard for all bots) Indicates the directories or URLs that can be accessed.
– Sitemap: Provides the URL to the site’s sitemap.
4. Wildcards
– Using `*` to represent any sequence of characters.
– Using `$` to specify the end of a URL.
5. Implementation
– Robots parse the robots.txt before crawling a website.
– Respects the directives unless the syntax is incorrect or ignored (e.g., by malware bots).
6. Examples
– To block all robots from the entire site:
“`
User-agent: *
Disallow: /
“`
– To allow all robots complete access:
“`
User-agent: *
Disallow:
“`
– To block a specific directory:
“`
User-agent: *
Disallow: /directory/
“`
Impact Robots.txt has on SEO
Robots.txt primarily affects a website’s SEO by directing search engine crawlers on how to interact with the website content. It controls which parts of the site are crawled and indexed by these bots, potentially impacting how content is discovered and ranked in search engine results.
1. Crawl Budget Management: By preventing crawlers from accessing irrelevant or redundant parts of a site, robots.txt helps conserve crawl budget. This ensures search engines spend more time and resources crawling and indexing valuable pages that contribute positively to SEO.
2. Prevention of Indexing Unwanted Pages: Robots.txt can prevent search engines from indexing pages that might hurt SEO if indexed, such as duplicate content, admin pages, or certain user information pages.
3. Indirect Impact on User Experience: Although robots.txt itself does not directly affect the user experience, by influencing which pages are indexed, it indirectly impacts what users find when they search for content related to the site. Ensuring only valuable and relevant pages are indexed can improve user satisfaction with search results.
4. Risk of Overblocking: Incorrect use of robots.txt can block search engines from indexing important pages, leading to decreased visibility and potential loss in traffic and rankings.
5. No Influence on Link Juice: While robots.txt blocks pages from being crawled, it does not prevent links to those pages from being followed. This means that even non-indexed pages can accumulate link equity, though they won’t pass it since they are not crawled.
6. Delayed Impact: Changes in robots.txt are not instantly recognized. Search engines must recrawl the file to notice and apply any updates, which can delay the desired effects on the site’s SEO performance.
In summary, properly configuring robots.txt is critical for effective SEO management, influencing how content is crawled and indexed, which in turn affects a website’s visibility and organic search performance.
SEO Best Practices For Robots.txt
1. Create or locate your website’s `robots.txt` file in the root directory (e.g., `https://www.example.com/robots.txt`).
2. Make sure to allow major search engines to crawl your site by including:
“`
User-agent: Googlebot
Disallow:
User-agent: Bingbot
Disallow:
“`
3. Block pages you don’t want search engines to index. For example, to block access to a private directory:
“`
User-agent: *
Disallow: /private-directory/
“`
4. Use the `Allow` directive to permit access to specific content within a disallowed directory:
“`
User-agent: *
Disallow: /private-directory/
Allow: /private-directory/public-information/
“`
5. Prevent search engines from indexing certain file types (e.g., PDFs or images):
“`
User-agent: *
Disallow: /*.pdf$
“`
6. Disallow search engine bots from accessing areas of your site that load dynamically or include personal customer data:
“`
User-agent: *
Disallow: /cgi-bin/
Disallow: /customer-accounts/
“`
7. Include sitemap locations to help search engines locate and crawl all allowable content efficiently:
“`
Sitemap: https://www.example.com/sitemap.xml
“`
8. Save changes to your `robots.txt` file.
9. Test your `robots.txt` file using Google Search Console’s robots.txt Tester tool to ensure that it blocks and allows content as anticipated.
10. Upload the updated `robots.txt` file back to your server if you made changes locally. Ensure it’s placed in the root domain (e.g., www.example.com/robots.txt).
11. Continuously review and update the `robots.txt` file as your website changes and grows.
Common Mistakes To Avoid
1. Disallowing All Crawlers: Using `User-agent: * Disallow: /` blocks access to the entire site, which can prevent indexing.
2. Blocking Important Content: Ensure you do not disallow directories or pages that are crucial for search engine understanding or for ranking the website.
3. Using Robots.txt for Privacy: Sensitive information should not be hidden using robots.txt; use proper authentication methods instead, as disallowing via robots.txt doesn’t guarantee privacy.
4. Overlapping or Conflicting Rules: Avoid contradictory directives for crawlers that can result from complex disallow and allow statements. Test for unintended disallow directives.
5. Syntax Errors: Adhere strictly to the correct syntax (spacing, colon usage, etc.) to avoid unintended crawling behavior.
6. Using Comments Incorrectly: Use comments correctly and strategically to clarify the purpose of different sections; incorrect placement might lead to ignoring valid directives.
7. Not Updating Robots.txt: Frequently review and update robots.txt to reflect new content strategies or structural changes in the website.
8. Misusing the Crawl-delay Directive: Use it judiciously; setting it too high can restrict site’s content being indexed effectively.
9. Oversight in Specifying Sitemap: Failure to indicate the sitemap location in robots.txt can hamper search engines’ ability to find and index content efficiently.
10. Accessibility of the File: Ensure robots.txt itself is accessible and not blocked by server settings or errors. Regularly check its status code is 200 OK.
11. Typos in User-agent or Paths: Even small typos can lead to big problems in which parts of the website are crawled.
12. Neglecting the Case Sensitivity of URLs: Remember that directives are case-sensitive to ensure accurate crawling restrictions.